Γιατί οι ψηφιακές συσκευές δεν… πολυαγαπάνε τα ελληνικά και τι μπορεί να γίνει για αυτό
Έξι επαγγελματίες αναδεικνύουν τα συστηματικά λάθη με τα οποία αποτυπώνονται οι ελληνικοί χαρακτήρες σε κινητά και υπολογιστές

Έχετε αναρωτηθεί τι γίνεται στο παρασκήνιο όταν διαβάζετε ή γράφετε ελληνικά σε κάποια ψηφιακή συσκευή; Αν όχι, σίγουρα θα έχετε παρατηρήσει ότι σε πολλά ψηφιακά περιβάλλοντα, από τα stories στο Instagram μέχρι τα λογισμικά επεξεργασίας βίντεο, οι περισσότερες γραμματοσειρές δεν υποστηρίζουν την ελληνική γλώσσα —και όταν το κάνουν, αυτό γίνεται συχνά με προβλήματα, όπως χαρακτήρες με περίεργη εμφάνιση κ.α.
Οι λόγοι για τους οποίους συμβαίνει αυτό είναι πολύ συγκεκριμένοι, και μία ομάδα επαγγελματιών, αποτελούμενη από σχεδιαστές γραμματοσειρών, τεχνικούς γραμματοσειρών (font engineers) και ακαδημαϊκούς, θέλησε να τους αναδείξει. Για αυτόν το σκοπό, δημιούργησε ένα διαδικτυακό ψήφισμα, με το οποίο θέλει να αναδείξει το πρόβλημα στους αρμόδιους (υπάρχουν τέτοιοι ακόμα και στο φαινομενικά αχανή και αρρύθμιστο χώρο της ψηφιακής πληροφορίας) και να εισηγηθεί τρόπους για την επίλυσή του.
Οι (κοινοί) κανόνες είναι για να σπάνε
Ο Κώστας Μπαρτσώκας, σχεδιαστής γραμματοσειρών ο ίδιος, ανήκει στην ομάδα ανθρώπων που δημιούργησαν το ψήφισμα. Σε επικοινωνία του με την Parallaxi, εξηγεί από πού ακριβώς ξεκινά το πρόβλημα:
«Όταν πληκτρολογούμε έναν χαρακτήρα στο πληκτρολόγιό μας, ο υπολογιστής δεν διαβάζει το χαρακτήρα αυτο κάθαυτό, αλλα έναν κωδικό που είναι μοναδικός για αυτόν τον χαρακτήρα. Έτσι, λοιπόν, κάθε λογισμικό μπορει να καταλάβει ποιον χαρακτήρα θέλουμε να πληκτρολογήσουμε», εξηγεί και προσθέτει: «Σε όλη αυτήν τη διαδικασία, παίζει κεντρικό ρόλο το Unicode Consortium, ένας μη κερδοσκοπικός οργανισμός. Αυτός διαχειρίζεται και αναπτύσσει το Unicode Standard, δηλαδή ορίζει έναν κωδικό για τον κάθε χαρακτήρα των γλωσσών παγκοσμίως, ώστε να αποδίδονται σωστά σε ψηφιακά περιβάλλοντα. Χάρη στο Unicode, μπορούμε να χρησιμοποιούμε διαφορετικές γλώσσες σε όλες τις σύγχρονες συσκευές και λογισμικά χωρίς να χρειάζονται ξεχωριστές ρυθμίσεις για κάθε γλώσσα».
Ωστόσο, η σωστή απόδοση μιας γλώσσας δεν εξαρτάται αποκλειστικά από το Unicode, καθώς σημαντικό ρόλο παίζουν επίσης:
- Οι εταιρείες λογισμικού (Microsoft, Apple, Google κλπ.), που ενσωματώνουν το Unicode στα λειτουργικά τους συστήματα και τις εφαρμογές.
- Οι τυπογράφοι και οι σχεδιαστές γραμματοσειρών, που δημιουργούν γραμματοσειρές οι οποίες πρέπει να τηρούν τις γλωσσικές και τυπογραφικές ιδιαιτερότητες κάθε γλώσσας.
- Οι φορείς προτυποποίησης, όπως ο ISO (International Organization for Standardization), που ορίζουν κανόνες για τη γραφιστική απόδοση και τη χρήση των χαρακτήρων σε τεχνολογικά περιβάλλοντα.
Όλοι οι παραπάνω φορείς, λοιπόν, λιγότερο ή περισσότερο αμέλησαν την ψηφιακή αποτύπωση της ελληνικής γλώσσας, με αποτέλεσμα να υπάρχουν σοβαρές δυσλειτουργίες στο πώς αυτή εμφανίζεται στους χρήστες.
Σύμφωνα με τον κ. Μπαρτσώκα, τα προβλήματα που συναντούν οι χρήστες περιλαμβάνουν:
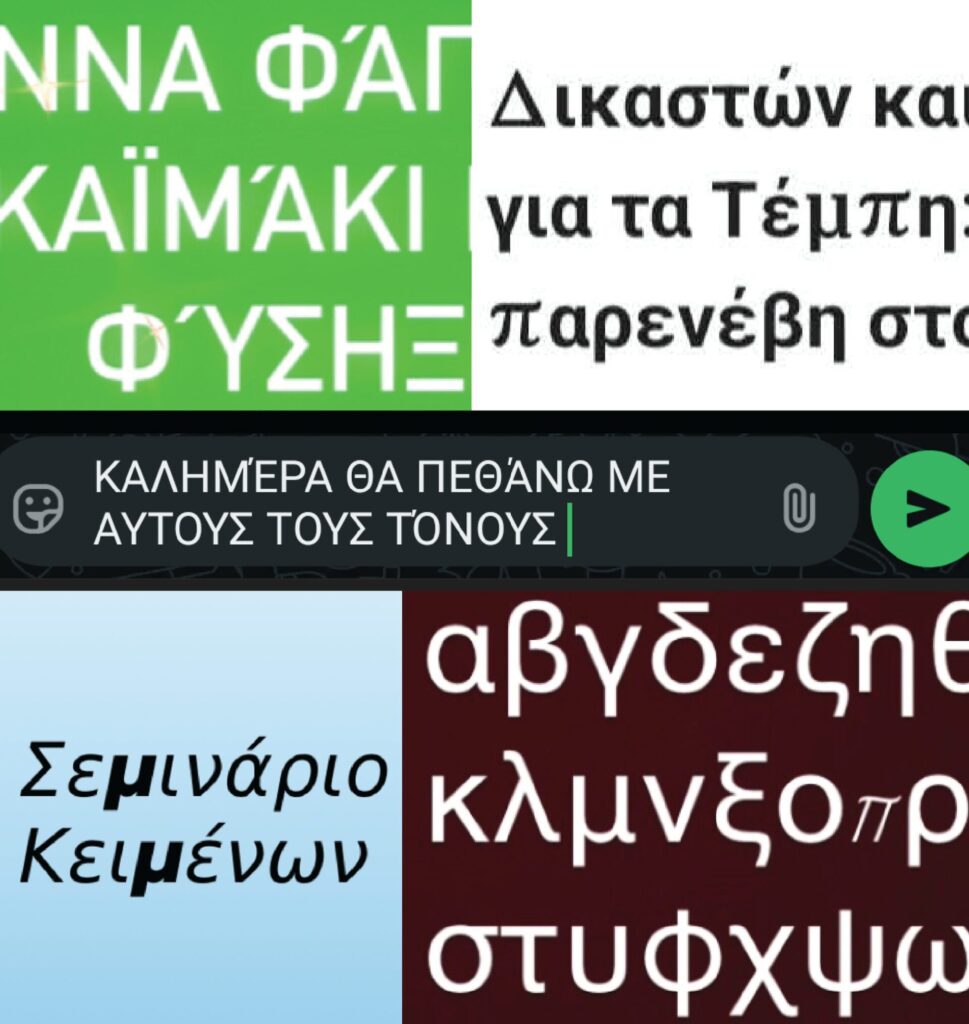
- Λάθος κεφαλαιοποίηση: Η μετατροπή των πεζών σε κεφαλαία (και αντίστροφα) γίνεται με λανθασμένους κανόνες, οδηγώντας σε λανθασμένη ορθογραφία και συχνα λανθασμένα τονισμένα τα κεφαλαία γράμματα.
- Προβλήματα στη στίξη: Για παράδειγμα, η άνω τελεία (·, U+0387) δεν αποδίδεται σωστά, με αποτέλεσμα να εμφανίζεται ως middle dot (·, U+00B7).
- Ασυνεπή πληκτρολόγια: Οι ελληνικοί χαρακτήρες και τα σύμβολα δεν είναι πάντα διαθέσιμα στα πληκτρολόγια των λειτουργικών συστημάτων, δυσχεραίνοντας τη χρήση τους.
- Λανθασμένη χρήση ελληνικών και λατινικών χαρακτήρων: Για παράδειγμα, το ελληνικό ερωτηματικό (;) συχνά αντικαθίσταται από το λατινικό semicolon (;), που μοιάζει οπτικά αλλά έχει διαφορετική σημασία.
Για τους γραφίστες και τυπογράφους τα προβλήματα είναι ακόμα σημαντικότερα, αφού επηρεάζουν τη ροή εργασίας τους. Συγκεκριμένα, έχουν να αντιμετωπίσουν:
- Κακή απόδοση των ελληνικών γραμματοσειρών: Τα ελληνικά εφαρμόζονται συχνά σαν «προσαρμογή» των λατινικών χωρίς να λαμβάνονται υπόψη οι τυπογραφικές ιδιαιτερότητές τους.
- Αποτυχία υποστήριξης βασικών χαρακτήρων: Πολλές γραμματοσειρές δεν περιλαμβάνουν απαραίτητα ελληνικά σύμβολα (π.χ. το ϗ ή τα αριθμητικά σημεία ʹ και ͵).
- Προβλήματα στο συλλαβισμό: Ο τρόπος που οι εφαρμογές «σπάνε» τις λέξεις στα ελληνικά είναι συχνά λανθασμένος, δημιουργώντας παράξενες ή ανορθόγραφες αποδόσεις.
Πρέπει να σημειωθεί ότι και στο παρελθόν είχαν γίνει μεμονωμένες κρούσεις από από τυπογράφους, προγραμματιστές και ερευνητές. «Μία από τις πιο σημαντικές προσπάθειες», μεταφέρει ο κ. Μπαρτσώκας, «έγινε στο συνέδριο Automatic Type Design 3 στην πόλη Nancy της Γαλλίας, όπου παρουσιάσαμε την έρευνά μας σχετικά με τα προβλήματα της ψηφιακής ελληνικής τυπογραφίας».
Ωστόσο, αυτές οι ενέργειες δεν είχαν συνοχή και δεν έλαβαν την απαραίτητη δημοσιότητα, ώστε να αλλάξει κάτι.
Και σε αυτό το ζήτημα, όπως και σε πολλά άλλα, ο μικρός αριθμός ομιλητών της ελληνικής γλώσσας παίζει σημαντικό ρόλο στον παραγκωνισμό της. Μάλιστα, το γεγονός ότι δεν είναι λατινογενής κάνει ακόμα πιο δύσκολο το να ασχοληθεί σοβαρά μαζί της η βιομηχανία τεχνολογίας.
«Επιπλέον, το ελληνικό αλφάβητο έχει μοναδικά χαρακτηριστικά, όπως τόνους, ιδιαίτερη κεφαλαιοποίηση, που δεν μεταφέρθηκαν σωστά από τα λατινικά πρότυπα», συμπληρώνει ο κ. Μπαρτσώκας. «Και φυσικά, να σημειωθεί ότι οι τεχνολογικές αποφάσεις λαμβάνονται από αγγλόφωνες ομάδες, που δεν έχουν επαρκή γνώση των ελληνικών γλωσσικών και τυπογραφικών ιδιαιτεροτήτων της συγχρονης γλώσσας».
Στην ερώτηση αν θα μπορούσαμε να κάνουμε λόγο για έναν ιδιότυπο γλωσσικό «ρατσισμό», απαντά: «Δεν θα χρησιμοποιούσα τον όρο “γλωσσικός ρατσισμός”, αλλά υπάρχει σίγουρα μια ανισότητα στη μεταχείριση των γλωσσών στην τεχνολογία. Οι γλώσσες με λιγότερους χρήστες, όπως τα ελληνικά, δεν έχουν την ίδια προτεραιότητα με τα αγγλικά, τα κινεζικά ή τα ισπανικά, που έχουν δισεκατομμύρια ομιλητών παγκοσμίως. Αυτό έχει ως αποτέλεσμα οι αναγκαίες διορθώσεις να καθυστερούν ή να μην υλοποιούνται ποτέ».
Οι στόχοι και τα επόμενα βήματα
Άμεσος στόχος των επαγγελματικών είναι αρχικά να φτάσει το ψήφισμα τις 5.000 υπογραφές. «Με αυτόν τον τρόπο, θα αποδείξουμε ότι το πρόβλημα αφορά όλους τους χρήστες της ελληνικής σύγχρονης γραφής, βασισμένης στους βασικούς κανόνες γραμματικής και ορθογραφίας, και όχι απλά την προτίμηση έξι επαγγελματιών», λέει ο κ. Μπαρτσώκας.

«Έπειτα, με τη βοήθεια τον υπογραφών, θα καταθέσουμε το αίτημα και θα οργανώσουμε συζητήσεις με στοχευμένους ανθρώπους απο το Unicode Consortium και τις μεγάλες εταιρείες λογισμικού (Microsoft, Apple, Google, Adobe κλπ.), που μπορούν να αλλάξουν το πεδίο της τεχνολογίας. Παράλληλα, θα προσεγγίσουμε ελληνικά και διεθνή ΜΜΕ, επιστημονικούς και πανεπιστημιακούς φορείς, καθώς και τεχνολογικές κοινότητες που μπορούν να βοηθήσουν στην τεχνική υλοποίηση των αλλαγών».
Τα αιτήματα προς το Consortium και τις εταιρείες μπορούν να συνοψιστούν ως εξής:
- Αναθεώρηση των κανόνων Unicode για τα ελληνικά.
- Δημιουργία μίας σωστής και ολοκληρωμένης τυπογραφική υποστήριξης της γλώσσας.
- Τυποποίηση των πληκτρολογίων σε όλες τις πλατφόρμες.
- Διόρθωση των προβλημάτων στις εφαρμογές επεξεργασίας κειμένου και design.
Μπορείτε να βρείτε το ψήφισμα εδώ.


