Μια λέξη στο Τwitter, χίλιες έννοιες
Επιμέλεια: Κύα Τζήμου Μια ομάδα ακαδημαϊκων ερευνητών (Daniel Preotiuc-Pietro από το Penn’s Positive Psychology Center, Nίκος Αλετράς και Βασίλειος Λάμπος από το University College London, Yoram Bachrach της Microsoft Research και Svitlana Volkova από το John Hopkins University) παίρνουν μέρος σε μια πολύπλευρη έρευνα πάνω στα δημογραφικά χαρακτηριστικά χρηστών στο Τουίτερ που περιλαμβάνει ακόμα την […]

Επιμέλεια: Κύα Τζήμου
Μια ομάδα ακαδημαϊκων ερευνητών (Daniel Preotiuc-Pietro από το Penn’s Positive Psychology Center, Nίκος Αλετράς και Βασίλειος Λάμπος από το University College London, Yoram Bachrach της Microsoft Research και Svitlana Volkova από το John Hopkins University) παίρνουν μέρος σε μια πολύπλευρη έρευνα πάνω στα δημογραφικά χαρακτηριστικά χρηστών στο Τουίτερ που περιλαμβάνει ακόμα την πρόβλεψη του επαγγελματικού κλάδου και της κοινωνικο-οικονομικής κατηγορίας που ανήκουν οι χρήστες αλλά και το υψος του εισοδήματος τους. Ο Νίκος Αλετράς μας εξηγεί απαντώντας στα ερωτήματά μας.
Ποια μέθοδο χρησιμοποιήσατε για να καταλήξετε σε συμπεράσματα μέσω της έρευνάς σας και ποια είναι η διαφορετική προσέγγιση στα «δείγματα» σας για την συγκέντρωση δεδομένων σε σχέση με άλλες έρευνες που έχουν γίνει για τα social media;
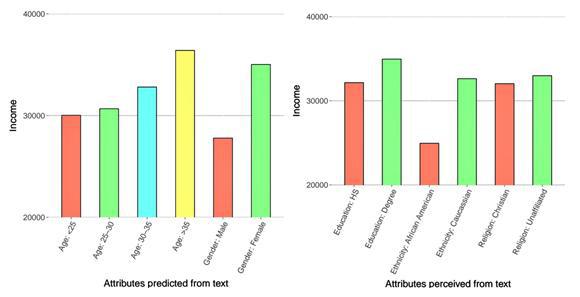
Το μοντέλο μας βασίζεται σε μη-γραμμικές μεθόδους μηχανικής μάθησης (machine learning), οι οποίες ονομάζονται Γκαουσσιανές Διαδικασίες (Gaussian Processes). Η βασική μας υπόθεση είναι ότι τα «θέματα» με τα οποία καταπιάνεται ο χρήστης στο Twitter είναι ενδεικτικά του εισοδήματός του (π.χ. οι χρήστες που «τουητάρουν» για πολιτική συνήθως έχουν υψηλότερο εισόδημα σε σχέση με αυτούς οι οποίοι δεν ασχολούνται με την πολιτική). Σε αυτή την κατεύθυνση μας οδήγησαν τα αποτελέσματα προηγούμενης έρευνάς μας όπου με ένα παρόμοιο μοντέλο, κατατάσσουμε τους χρήστες στην επαγγελματική κατηγορία όπου ανήκουν (π.χ. χειρονακτική εργασία ή βασικά επαγγέλαμτα γραφείου). Στο παρελθόν έχουν γίνει παρόμοιες έρευνες για διάφορα δημογραφικά χαρακτηριστικά των χρηστών στο Twitter όπως φύλο, ηλικία ή πολιτική κατεύθυνση όμως η έρευνά μας είναι η πρώτη που εξετάζει το εισόδημα. Ο αλγόριθμός μας «μαθαίνει» ακριβώς ποια συμπεριφορά από τους χρήστες μπορεί να το καθορίσει με ακρίβεια.
Όταν ξεκινήσατε την έρευνα ποιος ήταν ο στόχος της και ποια η χρησιμότητα των αποτελεσμάτων της; Μπορούν να αξιοποιηθούν από εταιρίες που εχουν συγκεκριμένες ομάδες στοχευσης και πως;
Ο στόχος μας είναι να εξετάσουμε τις γλωσσολογικές/γλωσσικές επιλογές διαφόρων ομάδων χρηστών στα μέσα κοινωνικής δικτύωσης. Ήδη εδώ και 50 χρόνια γλωσσολόγοι και ψυχολόγοι έχουν παρατηρήσει διαφορές στη χρήση της γλώσσας σε διαφορετικές ομάδες ανθρώπων και αυτό μας κίνησε την περιέργεια ώστε να το επιβεβαιώσουμε και στο Twitter. Βεβαίως, το μοντέλο που παρουσιάζουμε μπορεί να χρησιμοποιηθεί για στοχευμένη διαφήμιση. Λαμβάνοντας υπόψιν τις οικονομικές δυνατότητες του χρήστη, η μεθοδός μας μπορεί να συνδυαστεί με συστήματα προτάσεων (recommending systems) ώστε αυτά να προσαρμόζονται στην εκτιμόμενη αγοραστική ικανότητα του χρήστη.
Επίσης με το θέμα των προσωπικών δεδομένων των χρηστών παρέχεται κάποια ασφάλεια στη συγκεκριμένη περίπτωση;
Το θέμα των προσωπικών δεδομένων είναι πολύ σοβαρό και το λαμβάνουμε υπόψιν σε όλα τα στάδια της έρευνάς μας και γι’αυτό το λόγο δημοσιοποιούμε μόνο ό,τι επιτρέπεται από την πολιτική απορρήτου του Twitter.
Υπάρχει στην Ελλάδα έδαφος για να αναπτυχθεί έρευνα σχετικά με το αντικείμενό σας; Ποια είναι τα κυριότερα εμπόδια που θα αντιμετωπίζατε εδώ στην οργάνωση μιας έρευνας;
Προφανώς και υπάρχει καθώς η τεχνογνωσία και το ανθρώπινο δυναμικό δε λείπουν από τα ελληνικά Πανεπιστήμια. Αυτό που χρειάζεται είναι στοχευμένη χρηματοδότηση της έρευνας και συνεργασία μεταξύ δημόσιων και ιδιωτικών φορέων. Τέλος, δε νομίζω ότι θα συναντούσαμε κάποια ανυπέρβλητα εμπόδια στο να οργανώσουμε αυτή την έρευνα αν είμασταν στην Ελλάδα. Νομίζω το μόνο αναγκαίο θα ήταν σύγχρονος εξοπλισμός ώστε να μπορέσουμε να επεξεργαστούμε τα δεδομένα μας.
Πείτε μας λίγα πράγματα για σας: Σπουδές, προς ποια κατεύθυνση στρέφεται το επαγγελματικό σας ενδιαφέρον και γιατί.
Είμαι Επιστημονικός Συνεργάτης στο University College του Λονδίνου. Αποφοίτησα από το Τμήμα Επιστήμης Υπολογιστών στο Πανεπιστήμιο Κρήτης και συνέχισα τις σπουδές μου στο Πανεπιστήμιο του Σέφιλντ στο ΗΒ όπου και ολοκλήρωσα το διδακτορικό μου πάνω στην Επεξεργασία Φυσικής Γλώσσας (Natural Language Processing, NLP). Τα ερευνητικά μου ενδιαφέροντα περιλαμβάνουν Επεξεργασία Φυσικής Γλώσσας, Μηχανική Μάθηση και Υπολογιστική Σημασιολογία.

Δείτε περισσότερα για την έρευνα εδώ


